This is a followup to a prior blog post of mine, Sexism at NPR?, which garnered a mostly favorable response. Several of the NPR forum comments posed a few excellent questions and suggestions. My analysis covered years 2011 through 2015 and the graph below presents the same data broken down by year, demonstrating a clear trend.
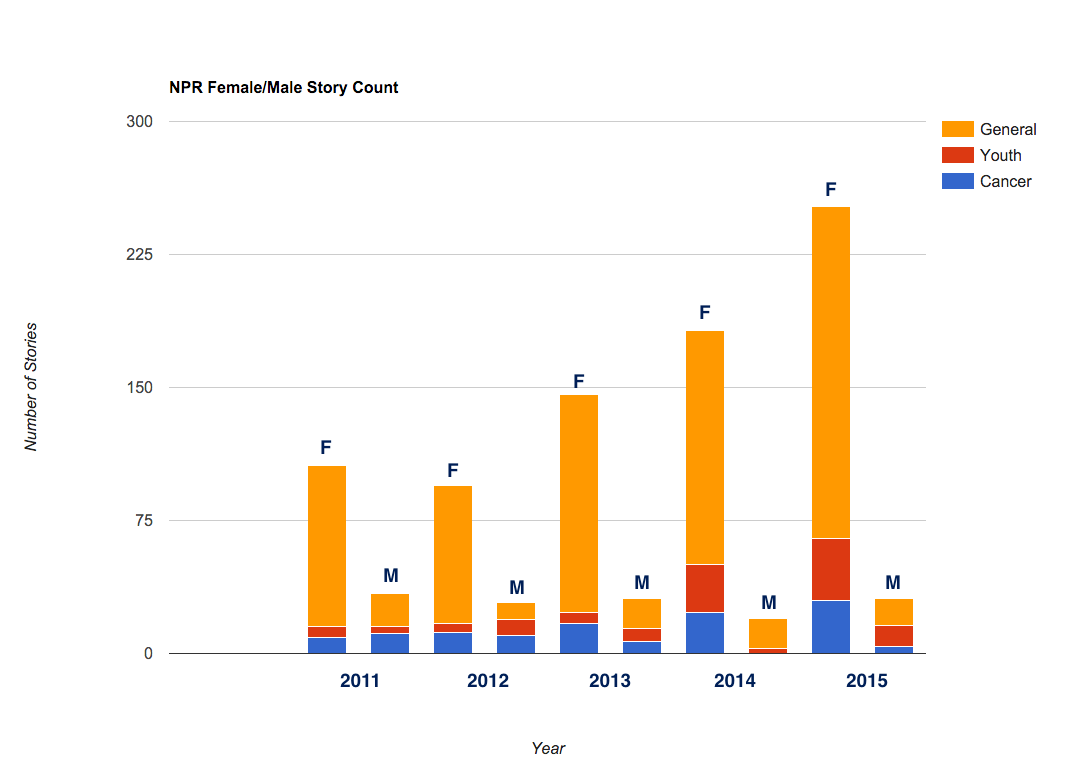
My prior analysis relied solely on NPR’s own tagging system of applying text labels to indicate story subjects. One of my readers posted on the NPR Ombudsman’s Facebook page and the response was “Well, I've written several times about how NPR's tagging is faulty--unfortunately it's just not a reliable way to analyze coverage”.
I’d generally agree that the tags aren’t perfect, but measuring their accuracy is a difficult task. Nevertheless, I took a few approaches and thought they might be interesting to present.
The program used for this analysis can be found at github.com/cmumford/news
“Gendered” Words
All of my analysis so far (and here too) relies on my list of a few gendered words. These were not meant to be all inclusive. I tried to be balanced, choosing equivalent words for each gender. These words (patterns, really) were used in several different analytical tests.
Male Words:
Adult: 'mens?', "men's", "man's", "father'?s?", "grandfather'?s?", 'grandpa', 'males?', 'masculism', "men's rights"
Youth: 'sons?', 'boys?', 'grandpa'
Cancer: 'prostate cancer’
Female Words:
Adult: ‘womens?', "women's", "woman's", "mother'?s?", "grandmother'?s?", 'grandma', 'females?', 'feminism', "women's rights?", 'ovarian transplant'
Youth: 'girls?', 'daughters?', '15girls'
Cancer: 'breast cancer'
Fuzzy words (patterns)
Note that some words, like ‘girls?’ have a question mark. The question mark means that the letter just before the question mark is optional. So, in this example, both ‘girl’, and ‘girls’ will match the ‘girls?’ pattern.
“Gendered” Word Counts
The first test was simply to look at every single word in every single story; to count the number of occurrences of each word, and then tally them up.
Female:Male
|
Counts
|
Ratio
|
girls?:boys?
|
13511:10227
|
1.32
|
women's rights?:men's rights
|
296:18
|
16.44
|
grandmother'?s?:grandfather'?s?
|
1800:1474
|
1.22
|
woman's:man's
|
946:1291
|
0.73
|
women's:men's
|
3432:1286
|
2.67
|
womens?:mens?
|
30810:19432
|
1.59
|
daughters?:sons?
|
7673:11691
|
0.66
|
ovarian transplant:<nothing>
|
4:0
| |
females?:males?
|
5732:4133
|
1.39
|
grandma:grandpa
|
432:159
|
2.72
|
mother'?s?:father'?s?
|
15102:13627
|
1.11
|
breast cancer:prostate cancer
|
1034:324
|
3.19
|
feminism:masculism
|
311:0
| |
Overall
|
81083:63662
|
1.27
|
Overall there were 81,083 “female” words and 63,662 “male” words in all stories equating to 27% more female words than male.
It’s difficult to learn much from this metric. A sentence like “my mother was a great cook” and “my mother was a horrible person” would each increment the female gender count by one, but the former is a positive statement about the mother, and the later is negative. This approach ignores any context, merely counting the number of gendered words.
Sentiment Analysis
Sentiment analysis is a fascinating topic. It’s an approach which, in it’s simplest form, uses lists of positive and negative words to analyze sentiment to determine whether a statement is positive or negative (and possibly how much) about a given subject.
Twitter and Facebook feeds are analyzed in order to determine public opinion using these statistical methods. This is one tool used by politicians to learn reactions to their speeches, policy decisions, etc.
Emotional Sentiment Counts
My first approach was to generate my own list of positive and negative (mostly) emotional words. I analyzed every sentence of every story. If the sentence contained a gendered word (see above), and contained a positive or negative word then I incremented the positive or negative count.
Positive words:
- accepted
- accepting
- approval
- cheer
- cheerful
- delight
- delightful
- devoted?
- funny
- generous
- good
- gregarious
- happy
- kind
- kindness
- liked?
- loved?
- romantic
- sacrificed?
- warm
Negative words:
- awful
- bad
- coward
- cruel
- deadbeat
- disapproval
- disapproving
- dislike
- hate
- hit
- hurt
- jail
- sad
- violent
The results were:
Female
|
Male
| |
Positive
|
9,247
|
7,182
|
Negative
|
1,643
|
1,645
|
This shows 29% more sentences with positive emotional female sentiment than men. Better systems (than mine) measure the weight of words; for example, “love” is more positive than “like”.
Overall Sentiment Counts
I then used a larger list of words called the Opinion Lexicon obtained from the University of Illinois at Chicago. The lists were much longer and contained much more than “emotional” words.
# positive words: 2014
# negative words: 4818
Doing the same analysis as above we get:
Female
|
Male
| |
Positive
|
43,213
|
33,225
|
Negative
|
42,492
|
36,048
|
If we calculate (net positive for women) / (net positive for men) then we get 55% more sentences with positive female sentiment than male.
Story Classification (i.e. tag generation)
NPR’s tags are a form of story classification. For example, NPR’s story 'Things Have Changed,' U.S. Judge Says Of Case Over Men-Only Military Draft has two tags: “women in combat” and “Pentagon”.
My classification approach used a natural language classifier which takes a statistical approach to classifying story text. This is the same, but simpler, approach used by SPAM filters to classify your email. Classifiers must be “trained” with example stories that are already tagged. My approach was to use stories with existing tags to train the classifier, which can then be used to tag (classify) other similar stories.
Generally, the more stories the better, but I was limited by the number of currently tagged stories. I only used stories with 17 or more common tags. These were the tags:
Women:
Tag Title
|
Matching Stories
|
Women's Health
|
348
|
breast cancer
|
87
|
women
|
52
|
women's rights
|
20
|
Total
|
507
|
Men:
Tag Title
|
Matching Stories
|
Men's Health
|
50
|
prostate cancer
|
28
|
Total
|
78
|
Result
I was surprised at the accuracy of the classifier given the limited number of stories used for training. I only applied a “gender tag” to stories that previously had no gender tag at all. These were the newly tagged stories:
New Tags
| |
Female
|
97
|
Male
|
18
|
Total
|
115
|
So there were (at least) 97 missing “female” tags and 18 missing “male” tags. I reviewed about ⅓ of them and did not find a single misclassified story. Generally the missing tags were in the same proportion (5:1) as existing tags.
Final Thought
Analyzing Twitter sentiments is a significantly easier task than analyzing news sentiment. A paper titled Large-Scale Sentiment Analysis for News and Blogs does a good job of explaining the difficulty of this task. I would say that the quick analysis presented here supports my hypothesis of a bias in favor of women at NPR — and that bias seems to be growing.
I must confess that I also became increasingly aware of my own bias when writing this story. I constantly had to check myself when selecting various words, or approaches, to this analysis to guard against collecting, even searching for evidence that would prove my hypothesis.
It’s only a matter of time until computer systems exist that will more accurately parse the meaning of sentences. I will be very interested to see how our perspective on a variety of subjects change once we get this magical power to analyze every word/picture/video ever written. I can’t wait!